해당 영상을 보고 정리한 글입니다.
https://www.youtube.com/watch?v=aQpa3hm9gE0
Clustered Index
Each InnoDB table has a special index called the clustered index that stores row data.
Typically, the clusterd Index is synonymous with the primary key.
InnoDB는 클러스터 인덱스라는 특별한 인덱스가 있고, 이는 primary key와 같다. (=동의어이다)

인덱스의 동작을 memtal representation으로 설명한 것.
데이터가 추가되면, 인덱스가 정렬되고, 이 인덱스는 각각의 row를 가리킨다.
하지만 실제 InnoDB의 동작은 이렇지 않다.

실제 동작은, row가 추가될 때마다, 해당 row가 순서상 앞선다면 그 밑의 row가 모두 밀린다.
성능적으로 이슈가 있어보이는데, 어떻게 되는건지 뒤에서 설명한다고 함
InnoDB는 데이터를 table space에 저장한다.
- InnoDB는 무조건 primary key가 필요하다.
- 그리고 그 기본키는 불변해야해하며, null이면 안된다.
- secondary indexes는 primary key를 right-most column으로 가지고 있다.
- 이말의 뜻은, 만약 secondary index가 데이터를 가지고 오는데 쓰인다면, 2개의 인덱스가 사용된다는 것이다.
- secondary Index가 primary index를 가리키고, primary index로 데이터를 가져오게 된다.
- 만약 기본키가 정의되지 않았으면, 첫번째 not null이고 unique한 컬럼이 쓰인다.
- 만약 이것도 없으면 InnoDB가 6 byte 짜리 hidden primary key를 만든다.
아래와 같은 이유로 성능 이슈 발생 가능
The problem with such key is that you don't have any control on it and worse,
this value is global to all tables without primary keys and can be a contention problem
if you perform multiple simultaneous writes on such tables(dict_sys -> mutex)
6바이트짜리 hidden primary key는 기본키가 없는 모든 테이블의 공용 값이라고 한다.
그 primary key 값은 dict_sys의 mutex에 의해 보호되므로
따라서 그런 테이블에 많은 양의 데이터를 insert하면 해당 뮤텍스에 대한 경합이 발생한다.
그러면 해당 테이블 뿐만 아니라 다른 테이블에도 광범위하게 영향을 줄 수 있는 것이다.
InnoDB Primary Key(3)
영상 11:13
기본키가 완전히 무작위하게 테이블에 데이터를 삽입하면,
하나 넣을 때마다 거의 모든 페이지가 건드려지는 것을 보여준다.
인덱스 트리의 균형을 다시 맞추기 위해(=rebalancing) 그런 것임
리밸런싱하는 과정에서 거의 모든 데이터가 이동한다.
⇒ 요약하자면, PK는 크기가 작고 sequential 하면 성능상 좋다는 것 같다.
InnoDB Primary Key (5)
DBA라면 아래와 같은 설정을 통해서 PK를 필수로 지정하게 할수 있다.
sql_require_primary_key를 1로 설정해두면, 기본키가 없다면 에러가 발생한다.
> SET sql_require_primary_key=1;
> CREATE TABLE nopk2 (i int not null, name varchar(2));Size matters

sbtest1의 기본키는 char(200)이다.
sbtest2의 기본키는 int(auto increment)이다.
이 중 뭐가 더 좋을까?
2번이 더 좋다. (char(200)이 int보다 크기가 더 크기 때문에)
CREATE TABLE 'sbtest1' (
) ENGINE=InnoDB DEFAULT CHAR table space를 확인해보면, 2번이 더 작은 것을 확인할 수 있다.

기본키의 크기를 작게 유지하면 secondary Index도 작게 유지된다.
따라서 기본키는 항상 작게 유지해야한다. (UUID 같은거 쓰면 안되겠다)
Secondary Index & Primary Key


위와 같은 테이블 (a, b, c를 cluster index로 쓰는 테이블)이 있고,
위와 같은 2개의 row가 들어있다고 하자.
ALTER TABLE t1 ADD INDEX f_idx(f);그리고 위의 alter 명령어로 f라는 secondary index column을 추가한다고 하자.
그러면 이 f index는 right_most column으로 기본키를 가지게 된다.

위 사진에서 오렌지색 부분이 숨겨진 Primary key 부분이다.

위와 같은 예시에서는 어떨까?
a, b는 varchar(10)이고
a, b, c를 기본키로 하고,
secondary index로 c(기본키의 일부), f, a에서 앞 두글자를 묶어서 인덱스로 만든다면?
secondary index의 right most column으로는 기본키 중 빠진 컬럼인 b만 포함될까, 전체 (a, b ,c)가 포함될까?
⇒ secondary index의 right most column으로 (a, b, c) 전체가 해당되게 된다.
GEN_CLUST_INDEX
MySQL의 InnoDB의 경우, 기본키(=클러스터 인덱스)가 없는 테이블을 생성할 경우 컬럼이 NOT NULL로 구성된 UNIQUE KEY가 있을 경우 클러스터로 사용한다.
별도의 키가 없을 경우, GEN_CLUST_INDEX라는 이름의 클러스터 인덱스가 생성된다.
(6바이트의 크기, 물리적으로 저장된 순서로 인덱스 값이 부여된다.)
이 GEN_CLUST_INDEX를 쓴다는 것은, 기본키가 정의돼 있지 않다는 것이다.
아래와 같은 쿼리를 날릴 경우, GEN_CLUST_INDEX를 쓰는 테이블을 볼 수 있다.
selec i.table_id, t.name
from information_schema.innodb_indexes i
join information_schema.innodb_tables t on (i.table_id = table_id)
where i.name = 'GEN_CLUST_INDEX';이 보이지 않는(invisible) id를 같이 보고 싶다면, select 절에 명시해주면 된다.
아래 쿼리를 날리면, id도 함께 보임
select id, a.* from actors a;GIPK Mode
MySQL의 8.0.30부터 GIPK 모드를 쓸 수 있다.
GIPK Mode의 의미는 “Generated Invisible Primary Key”이다.
GIPK Mode는 “sql_generate_invisible_primary_key” server system variable에 의해서 컨트롤된다.
GIPK 모드가 활성화되면, primary key가 없는 테이블이 생성될 때마다, “my_row_id”라는 이름의 기본키 컬럼이 생성된다.
아래는 “show create table” 명령어의 실행 결과와 “select” 명령에서 my_row_id를 함께 조회한 결과이다.

auto_increment에 대한 이야기
auto_increment 컬럼의 타입에 따라, 테이블에 넣을 수 있는 데이터 양의 한계가 정해진다.
예를 들어, primary key의 타입이 tinyint이고, auto_increment라고 하자.
그럼 그 테이블은 id 값을 최대 127까지 밖에 넣을 수가 없다.
만약 128번째 Insert가 들어오게 되면 더이상 넣을 수 없다는 error가 발생한다.
아래는 Auto-Increment Value Exhaustion이 얼마나 진행됐는지 요약을 볼 수 있는 쿼리이다.
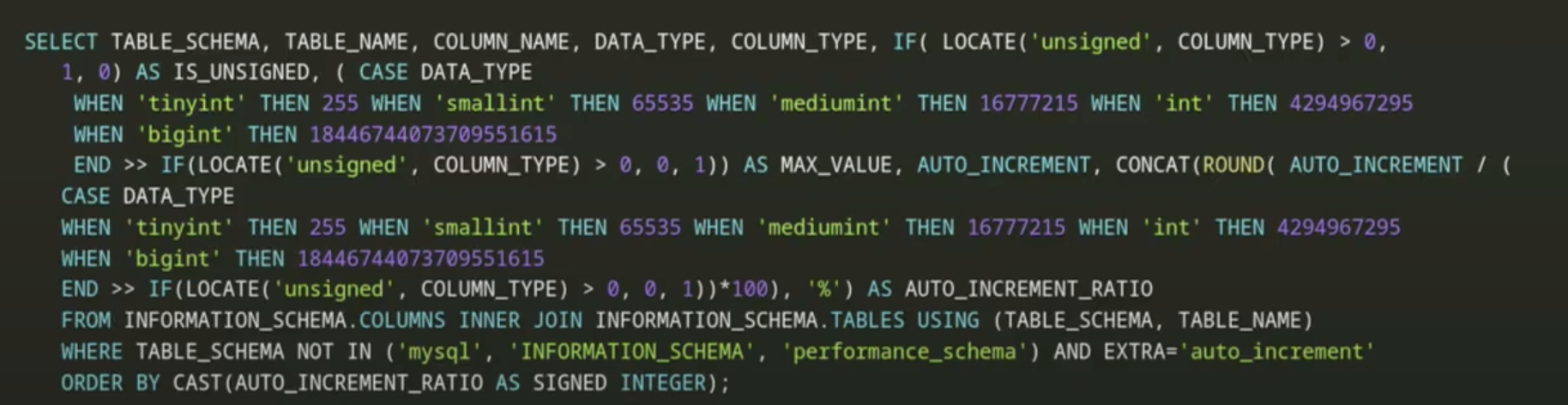
결과 예시.

가장 좋은 것은, 데이터 양이 많을 것 같은 테이블은 auto_increment 컬럼의 타입을 BIGINT UNSIGNED로 만드는 것이다.
SERIAL
auto_increment 말고도, serial로도 자동 증가 기본키를 만들 수 있다.
SERIAL의 사용 예시
CREATE TABLE scott (
id serial,
name varchar(10),
inserted DATETIME default current_timestamp,
primary_key(id, name)
);Replication & HA 측면에서의 PK
Replication
왜 PK가 없는 테이블을 복사하는게 느릴까?
인덱스를 타지 않는 DML을 실행하면, full table scan을 하게 된다.
아래와 같은 query를 실행 했을 때, 5개의 row를 지우기 위해 11개의 row를 다 스캔했다는 것을 알 수 있다.
이와 같은 상황에서 데이터가 테라바이트 단위로 많아지게 되면 지연이 발생할 수 밖에 없다.

이런 상황에서 GIPK 모드를 활성화하면 좋다.
*참고:
statement-based replication이란 명령문 기반 복제라는 의미로, MySQL 3.23부터 가능했다.
바이너리 로그에 마스터에서 실행된 SQL문이 단순하게 기록되는 방식이다.
row-based replication이란 행 기반 복제라는 의미이다.
마스터에서 변경된 데이터 레코드를 기록하는 방식이다.
마스터-슬레이브 구조에서 statement-based가 row-based에 비해서 슬레이브에 전송해야할 데이터 양이 적다는 장점이 있다.
정리하자면, GIPK 모드를 활성화하면 마스터-슬레이브 구조에서 행 기반으로 데이터를 복사할 때 좋다는 뜻인 것 같다.
HA
마스터-슬레이브 구조에서 group replication을 할때, 그 테이블은 PK 또는 PK에 준하는 not null unique 컬럼을 가지고 있어야 한다는 의미인듯
왜냐하면 마스터-슬레이브 같은 그룹 환경에서 데이터를 복사할 때 “certification”이라는 과정을 거쳐서 트랜잭션이 충돌하지 않도록 하는데 이 cerificationr과정에서 PK가 필수적이라는 의미인 것 같다.
migration(dump & load) 관점에서의 PK
mysqldump 명령어와 GIPK
“create_invisible_pks”이라는 MySQL Shell Dump Utility의 compatibility option은 dump가 일어날 때, PK가 없는 모든 테이블의 보이지 않는 PK를 불러오도록 한다.
dump된 데이터 는 dump loading utility에 의해 처리되기 전까지는 보이지 않는 PK가 포함되지 않는다.
UUID를 PK로 쓰면 어떻게 될까?
57분 부근
char(36) 타입의 uuid를 PK로 쓴다면 어떻게 될까?
앞에서 sequential하지 않고(=pk가 랜덤하고), pk의 크기가 크면 리밸런싱이 많이 발생한다고 했다.
uuid는 PK의 크기도 큰 편이고, 규칙적으로 증가하지도 않기에 리밸런싱이 광범위하게, 자주 발생한다.
이거에 대한 대안으로, 강의자는 “UUID_TO_BIN” 함수를 사용하여 UUID를 좀더 크기가 작은 binary(16)에 담을 것을 제안하고 있다.
정리..?
- secondary index 컬럼은 right-most 컬럼으로 pk를 사용한다.
- pk는 sequential하고, 크기가 작을 수록 좋다. (트리의 리밸런싱이 일어날때 영향을 미치는 페이지가 적음)
- 만약 기본키가 없다면, 데이터 삽입시에 unique not null인 다른 컬럼이 클러스터로 사용된다.
- 만약 unique not null 컬럼도 없다면, 6 byte짜리 숨겨진 pk를 만든다. (GEN_CLUST_INDEX)
- 설정을 통해 create 문 실행시 무조건 PK가 명시적으로 포함되도록 제한할 수 있다.
- GIPK(Generated Invisible Primary Key) 모드를 활성화하면, PK가 없는 테이블에는 자동으로 my_row_id 컬럼이 만들어진다.
- 이는 행 단위 replication에 도움을 줌.
- BIGINT UNSIGNED NOT NULL AUTO_INCREMENT UNITQUE를 모두 포함한 “serial”이라는 타입이 존재한다.
- 참고로, PK의 타입 크기는 들어갈 수 있는 데이터 개수 한계를 결정하므로, 데이터가 많을것으로 예상된다면 BIGINT UNSIGNED로 하는 것이 가장 좋다.
- 데이터가 더이상 못들어갈 때까지 꽉차게 되면, PK의 타입을 더 큰걸로 바꿔주어야함
GIPK Mode와 GEN_CLUST_INDEX에 대한 보충 영상
https://www.youtube.com/watch?v=ojmHqzixnUU
GIPK에 대한 내용은 이게 좀더 이해가 잘 가는것 같다.

이런 PK, unique not null 없는 테이블을 만들고

GEN_CLUST_INDEX를 쓰는 테이블을 조회해보면, 아까 만든 테이블이 보이는 것을 확인할 수 있다.

이제 "set sql_generate_invisible_primary_key=1;"을 통해 gipk 모드를 활성화해보자

그리고 아까와 똑같은 ddl로 mytable2를 만들고, GEN_CLUST_INDEX를 쓰는 테이블을 조회해보면
mytable2는 보이지 않는다.
그리고 select * from mytable을 해도 pk는 보이지 않는다.

show create table 명령어로 봐도 보이지 않음

이 "show_gipk_in_create_table_and_information_schema"를 1로 활성화해주면 my_row_id를 볼 수 있다.


가장 좋은건 테이블을 설계하고 처음 만들때 pk를 잘 설정해주는 것이다.
솔직히 이 영상을 보면서 애초에 pk가 없는 테이블을 만들일이 없지 않나..라는 생각이 들었다
그런데 진짜 어쩌다가 실수로 테이블을 잘못 설계해서 pk나 not null unique가 없는 테이블을 만들게 되었다면 GIPK모드는 되게 유용할 것 같다.
그런 보험(?)의 느낌에서 GIPK 모드를 켜놓는게 좋을 것 같다는 생각이 들었다.
Reference
'개념 공부 > DBMS' 카테고리의 다른 글
| [Oracle] 함수 기반 인덱스란? (2) | 2025.04.19 |
|---|---|
| [Redis] Redis 데이터의 영구 저장(RDB, AOF) (1) | 2024.12.10 |
| [DBMS] 트랜잭션(Transaction)이란 (0) | 2024.09.02 |
| [Beyond SW / 7일차 복습 - 2] 정규형, DB Dump 실습 (3) | 2024.05.26 |
| [Beyond SW / 7일차 복습 - 1] 데이터모델링 (3) | 2024.05.22 |



